
How To Build Your Own Feedback Analysis Solution
Plus learnings from talking to 1700+ insights & research experts over the past 8 years
At Thematic, we’ve spent years designing and developing our customer feedback analysis platform. While I’d love for everyone to be using ours, I understand that you might have the resources and the time to build your own in-house.
There are benefits to building vs. buying, and there are also many gotchas that you will need to consider. We'll discuss these towards the end of this post.
But the main purpose of this post is to share with you what we've learned over the past years. Since we started Thematic AI technology has evolved rapidly. This is a 2024 revision of this article with a focus on Large Language Models.
We'll cover:
- How to design a feedback analytics solution with users in mind
- Which language models are the best at feedback analysis
- What types of analysis should a feedback analytics solution support
- How to ensure accuracy and consistency
- How to think about data storage, ingestion and GDPR
- How to build a visual front-end for reporting
- What are the advantages and disadvantages of building your own solution
The learnings here will cover thousands of conversations with our customers and prospects. We counted over 1700 experts from around the world who work in research, insights and Customer Experience. Our own solution benefited from their input, ideas and, you guessed it, their feedback!
How to design a feedback analytics solution with users in mind
Before building a feedback analysis solution, start by conducting your own research. Who are your users? What are their needs? Most likely, their current situation fall into one of the 3 cases:
- They have been analyzing feedback manually
- They used rule-based approaches in feedback management platforms like Qualtrics or Medallia.
- They put feedback into ChatGPT / Copilot or similar tools.
Make sure to ask what they like and dislike about these solutions. Don't rush to dismiss what their experience in favor of a new shiny thing. We found that each method has its advantages and disadvantages. Here's what we've learned from insights experts who we've talked over the years:
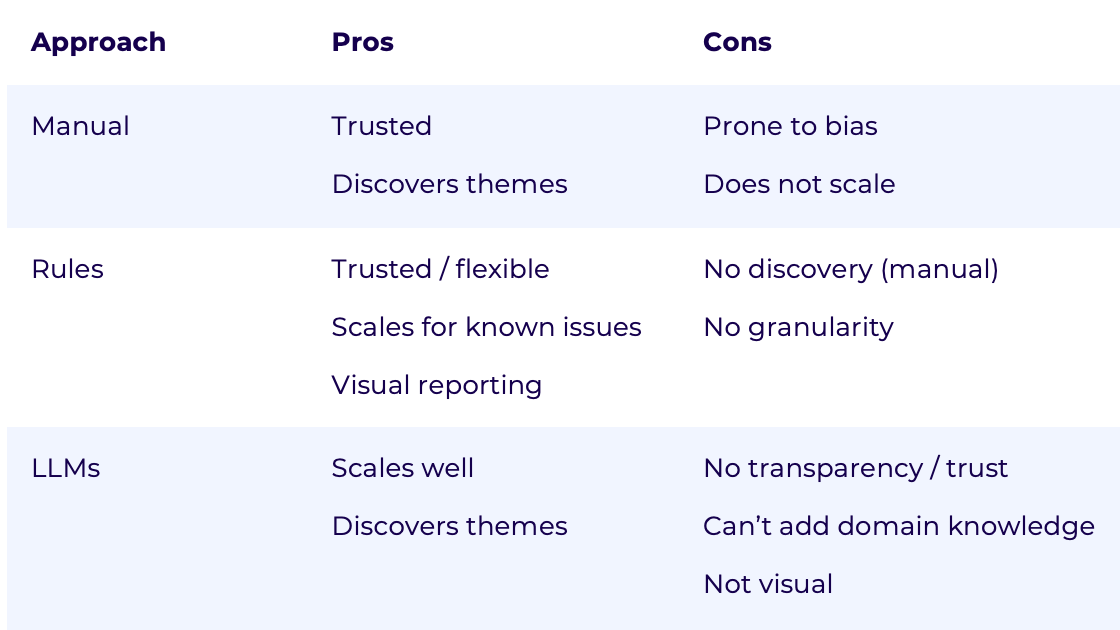
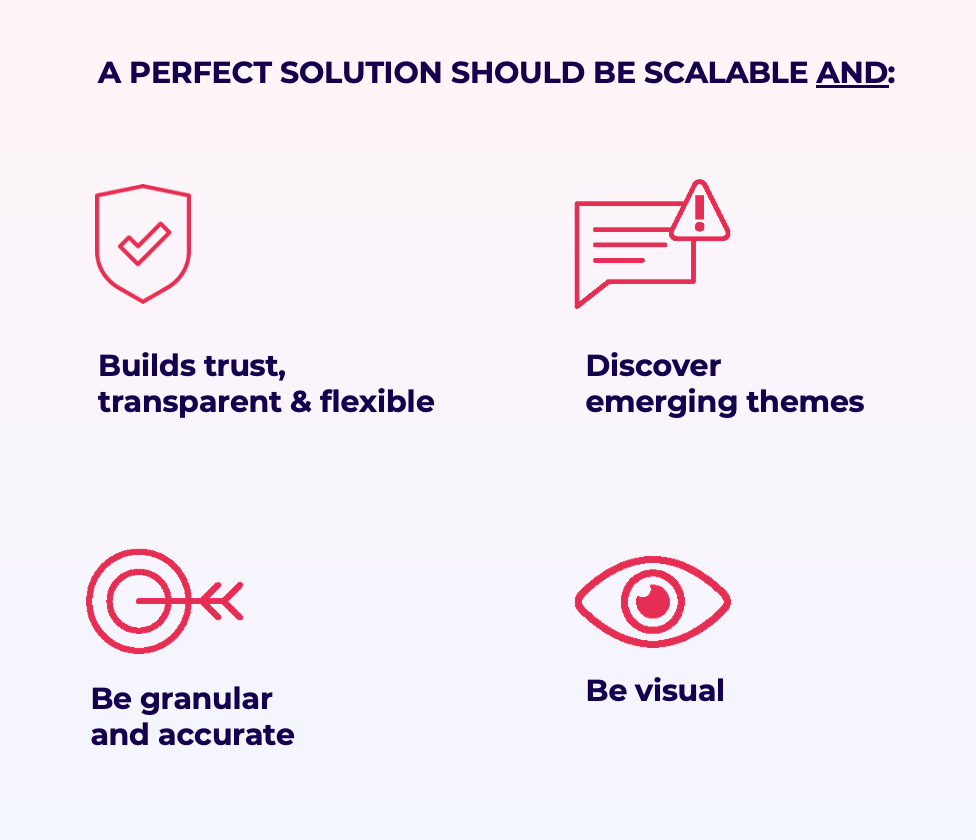
Trust plays a huge role in analyzing data. If you lack transparency about how feedback was analyzed, researchers won't adopt your solution.
Discovery of insights is critical. Users want alerts about any new themes emerging in feedback and any unusual spikes in volume. They also want a system that picks up new ways of how people might be referring to existing issues.
Granularity of insights is key too. It's easy to group feedback into 10 categories. It's hard to create a solution that lets you zoom in and out of the data. Users like seeing both the top-level issues, the sub-themes and actual comments.
Finally, visual insights are key. It's impressive to ask a question and get a brief answer. But, most data is best consumed visually. And by this I don't mean word clouds! Decision makers want charts that explain trends. They should help the decision makers size up issues and their impact and be backed up by the data.
Finally, read up on frameworks and playbooks for analyzing feedback at scale. For example, Intercom has a great blog post on this topic.
To LLM or not to LLM: Which language models are best at feedback analysis
Language models are the de facto tools for analyzing and understanding language. There are many different types of language models. Best solutions combine them, capitalizing on their individual strengths.
Large Language Models, such as GPT, Claude, and Cohere, provide deep language understanding. From our experience, LLMs are highly competent at detecting themes and understanding sentiment. They are among the most sophisticated technologies for summarizing and paraphrasing text. They can identify root causes and interpret questions. They are robust in handling typos, misspellings, and jargon.
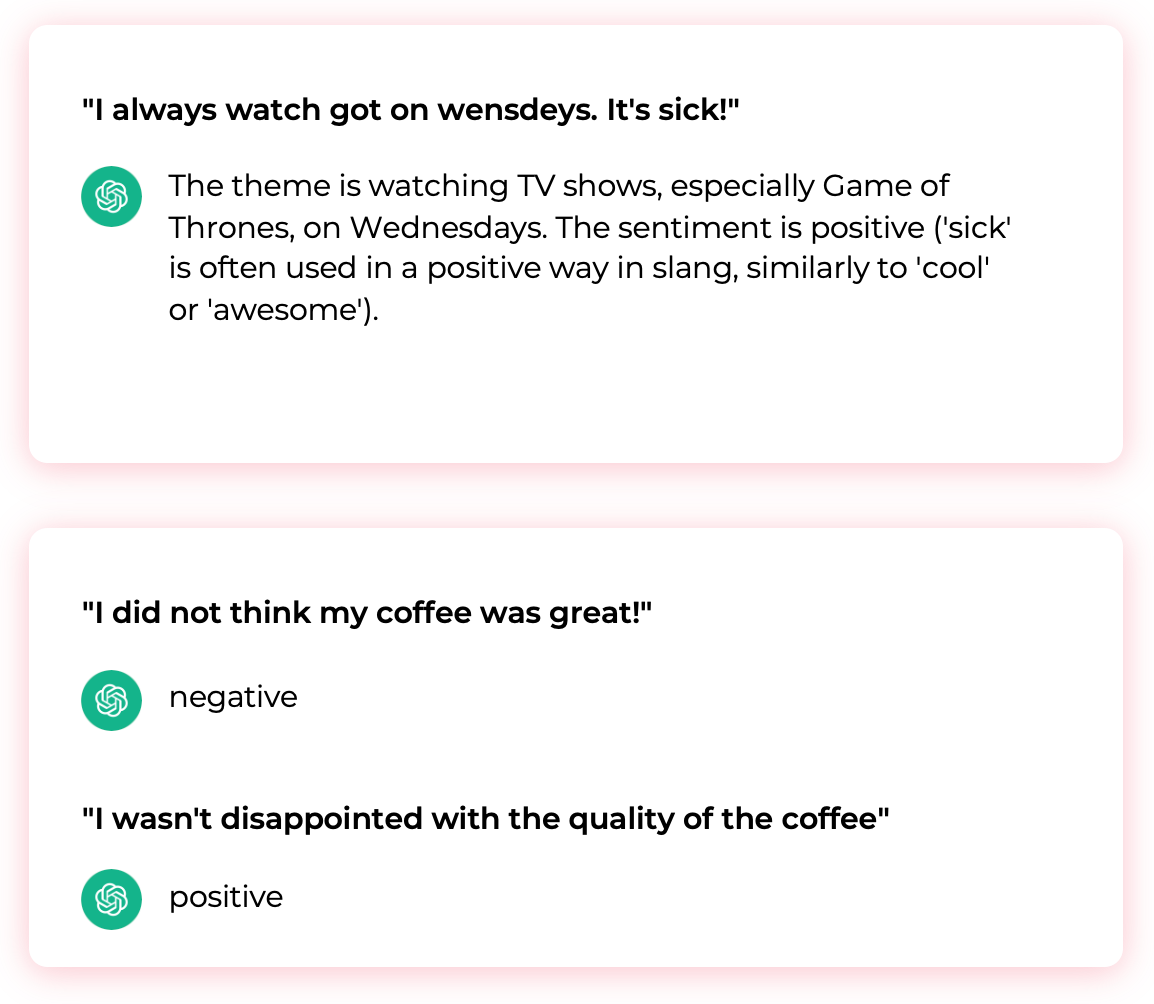
LLMs are the natural choice for analyzing feedback, but they have limitations. Everyone talks about the costs and the hallucinations. Yes, these are valid limitations. Over time we expect them to become manageable. But there is a more critical limitation to address when building your own feedback analytics solution. It's the lack of trust.
As discussed earlier, trust is critical for researchers. An LLM-based solution needs to earn that trust through various means. It could be a user interface, a way of interrogating data, or strict guardrails they can check. Below is our summary of related user needs and LLMs' limitations we encountered.

Should you use other language models in your solution? While LLMs are often the go-to choice, it's worth considering the integration of traditional language models such as categorization, topic modeling, embeddings, and clustering into your analytical framework. These models can complement LLMs, potentially helping fix their limitations or maximize their power.
There are several classes of solutions that are now outdated:
- NLP APIs for keyword and theme extractions. They have poor coverage, zero flexibility or transparency.
- Open-source NLP libraries for extracting keywords and categories. I'm an author of several such libraries, and still ready to say goodbye to them.
Our overall recommendation: Don't ditch the old models, but combine and enhance. By retaining the strengths of older methods and iteratively improving them through the use of LLMs, you can create the most effective solution.
What types of analysis should a feedback analytics solution support
Now that you know which language models are best, let's review the components you need to build.
1. Transcription of feedback
Not all feedback comes in text form. Multi-modal LLMs such as GPT-4o can analyze and interpret audio. But for a consistent analysis across feedback channels, it's best to transcribe the audio. For this, you need ASR (automatic speech recognition) and STT (speech to text).
Your audio file is usually multi-channel or multi-track. Each track records text from a single source, as visualized below:
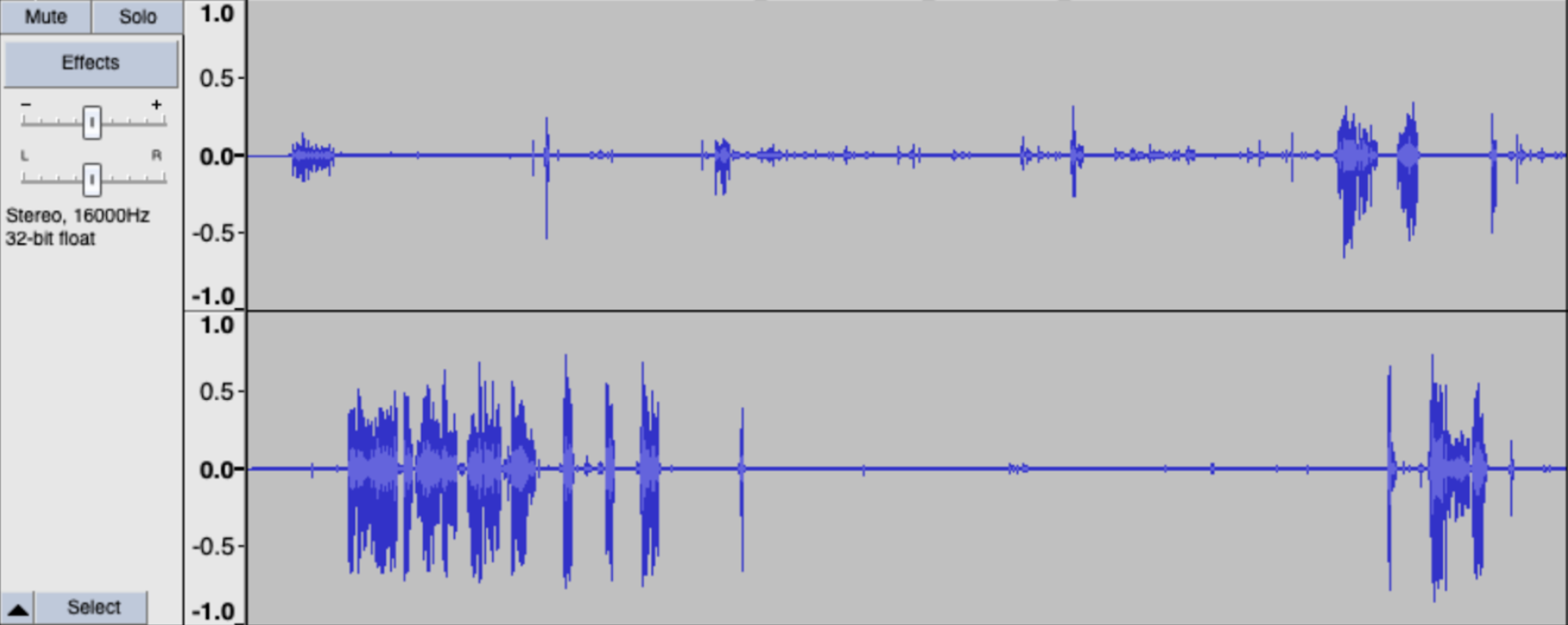
The top channel is from the operator, the bottom channel from the client. Generally, the audio starts with the operator's greeting, such as "Hi, how can I help you". Sometimes it's not the case and you'll need to clean transcribed data by re-labeling the tracks.
We recommend testing Amazon Transcribe, Google Speech-to-Text and OpenAI's Whisper. When deciding which engine is best, consider accuracy, price, and file size limits. Some services offer speaker diarization, others don't. We've observed that sometimes LLMs do hallucinate strange text in quiet audio parts. You are likely to have to clean transcribed text to remove it.
2. Translation of feedback
At Thematic, we translate feedback from other languages into English before analyzing it. This provides consistency to our customers who look at trends across markets. To save on translation costs, we recommend using a language guessing library first.
If you only use LLMs for analysis, translation might not be necessary. It's best to test various prompts on a variety of feedback in your dataset.

3. Redaction of feedback
Contact center data often contains personally identifiable information (PII). This includes people's names, addresses, phone numbers, emails, and policy numbers. Text feedback can even have credit card numbers and CCV/expiry dates. Will you display any of the original feedback in the final solution for users to read? In this case, you'll need to redact this data first.
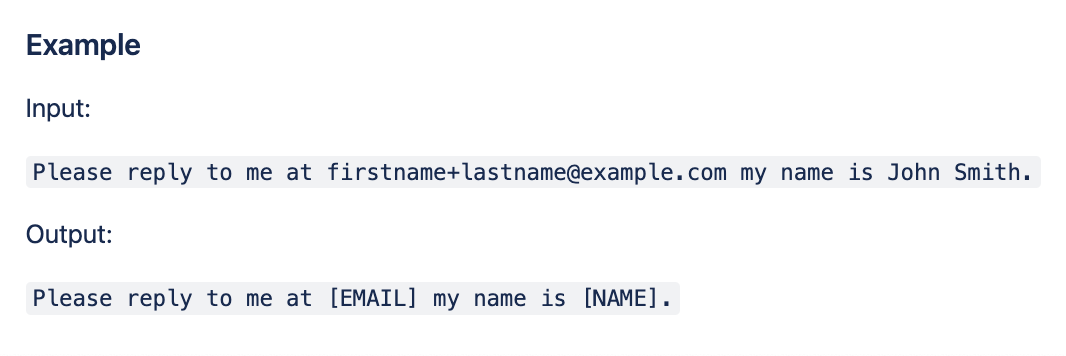
There are many redaction libraries available on GitHub. Most likely you'll need to customize them to fit your needs. Alternatively, Amazon Comprehend has a redaction API. Note that if you use that API, your data will be leaving private hosting environment.
4. Themes
Themes are the most critical part of the analysis. Your users want to understand the most common themes at a high and at a granular levels. They'll want to quantify their importance and track them over time.
When your feedback dataset is small (a few hundred comments), things are simple. We described in detail how to analyze your feedback using ChatGPT.
For medium and large datasets, you could get away with discovering themes and sub-themes using an LLM. But most solutions combine LLMs with traditional methods. They do this to save on costs and time. For example, you could categorize feedback into 10 key categories, and then use LLMs to group feedback within each category. Or you could apply LLMs first to scale the data. Then, apply topic modeling to turn the feedback into vectors. The diagram below shows how it's done in Microsoft's AllHands system.
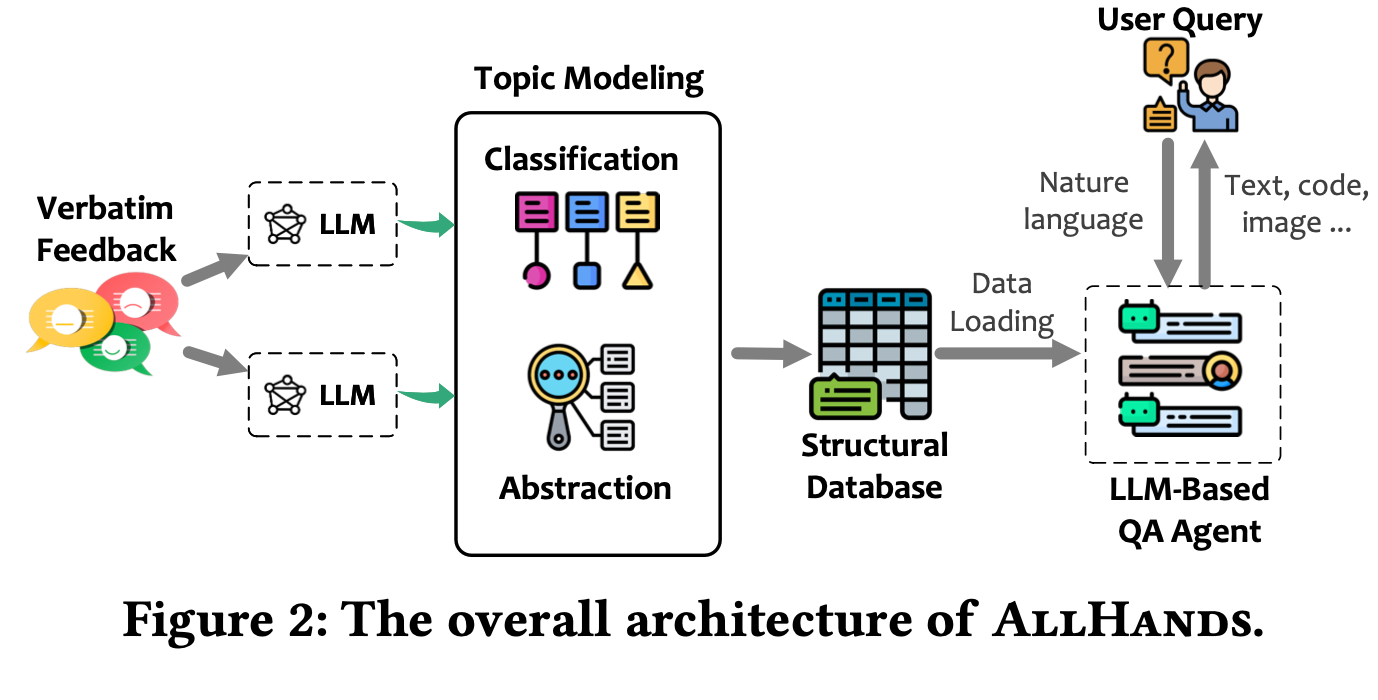
Here are several posts and research papers that explain how others have applied LLMs to extract themes from feedback:
5. Sentiment
Users often need to filter feedback and themes by sentiment. Best solutions can differentiate between positive, neutral and negative. Sometimes users want to know more specific emotions such as anger, confusion, delight. We found that knowing such granular emotions does not change how you might act on this data.
There are two options for sentiment analysis. Capture it within a theme (e.g. "easy to create an account") or attach it to a theme (e.g. "ease of creating account" + positive). Here are some examples:
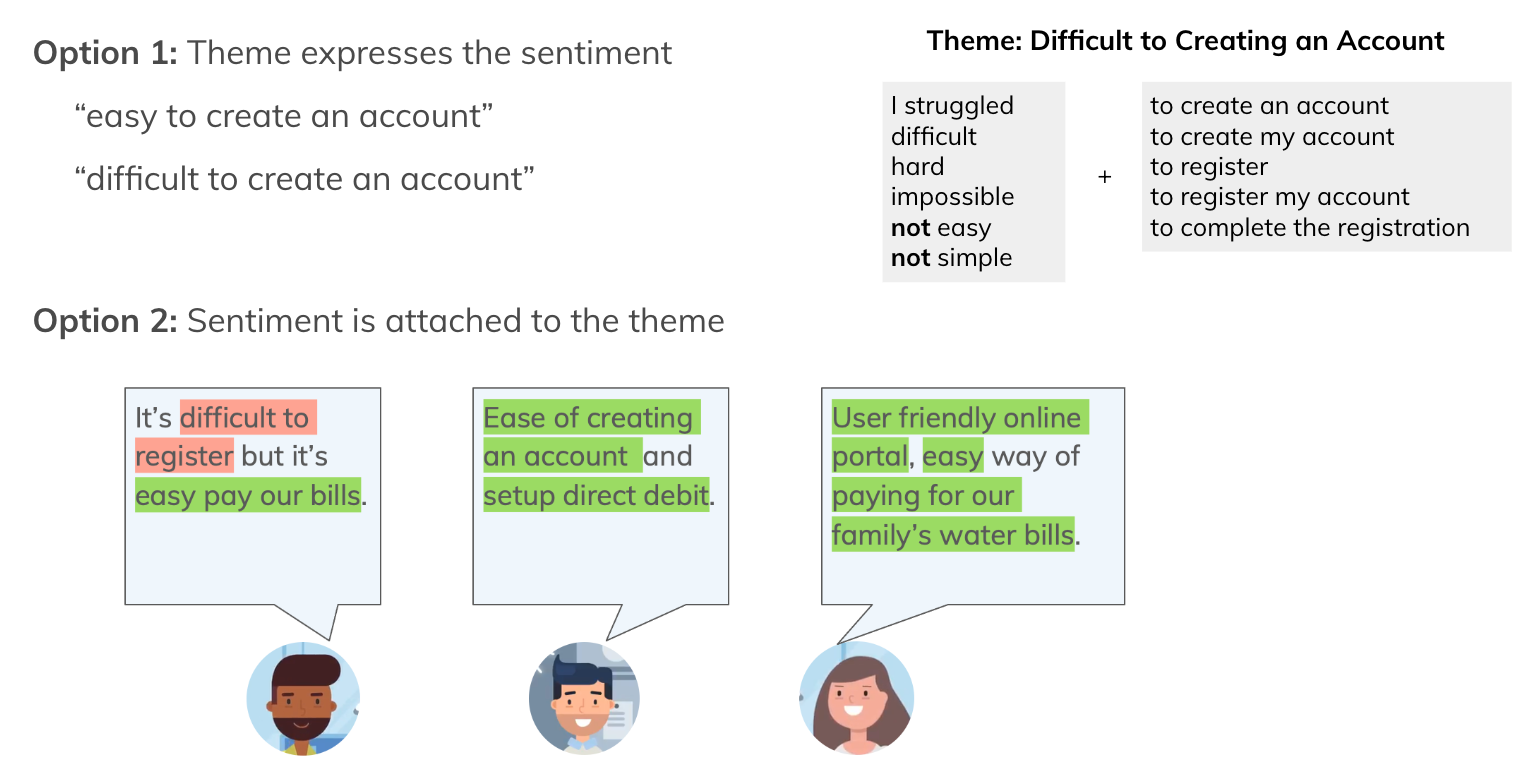
There are pros and cons to both, so we recommend to combine both depending on how frequent the themes are:

How to achieve this? You could write a prompt that tells LLM to find themes, but exclude sentiment, or vice versa. A separate sentiment library could analyze the sentiment of sentence snippets. Or you could tell the LLM to list both sentiment and theme for each sentence (and their index in source sentence). It's best to experiment and evaluate different approaches.
Beware that if you ask the LLM to list segments and their sentiment, it might hallucinate the exact wording of the original text. So if you need to highlight this data later in your user interface, this might cause issues. Make sure to use proper data storage techniques in this case.
6. Summarization
Feedback looks different depending on how people left it. But it can also differ depending on your company's products and services. For example, unhappy reviews for a bank app can be short and sweet, but for a weight loss app they are long and detailed. Surveys are different from complaints. Sales notes are a whole different beast that might have customer feedback.
We found that anything conversational needs a unique approach. Let's say you want to gather what people say about a new feature across feedback channels. To ensure consistency and reduce hallucinations, you could summarize each conversation first. For a chat log, this summary would say why a customer contacted you and the resolution.
At Thematic, we link each summary segment to the original sources for validation. A unified view guides the user about the most common reasons for contacting you and shows trends.
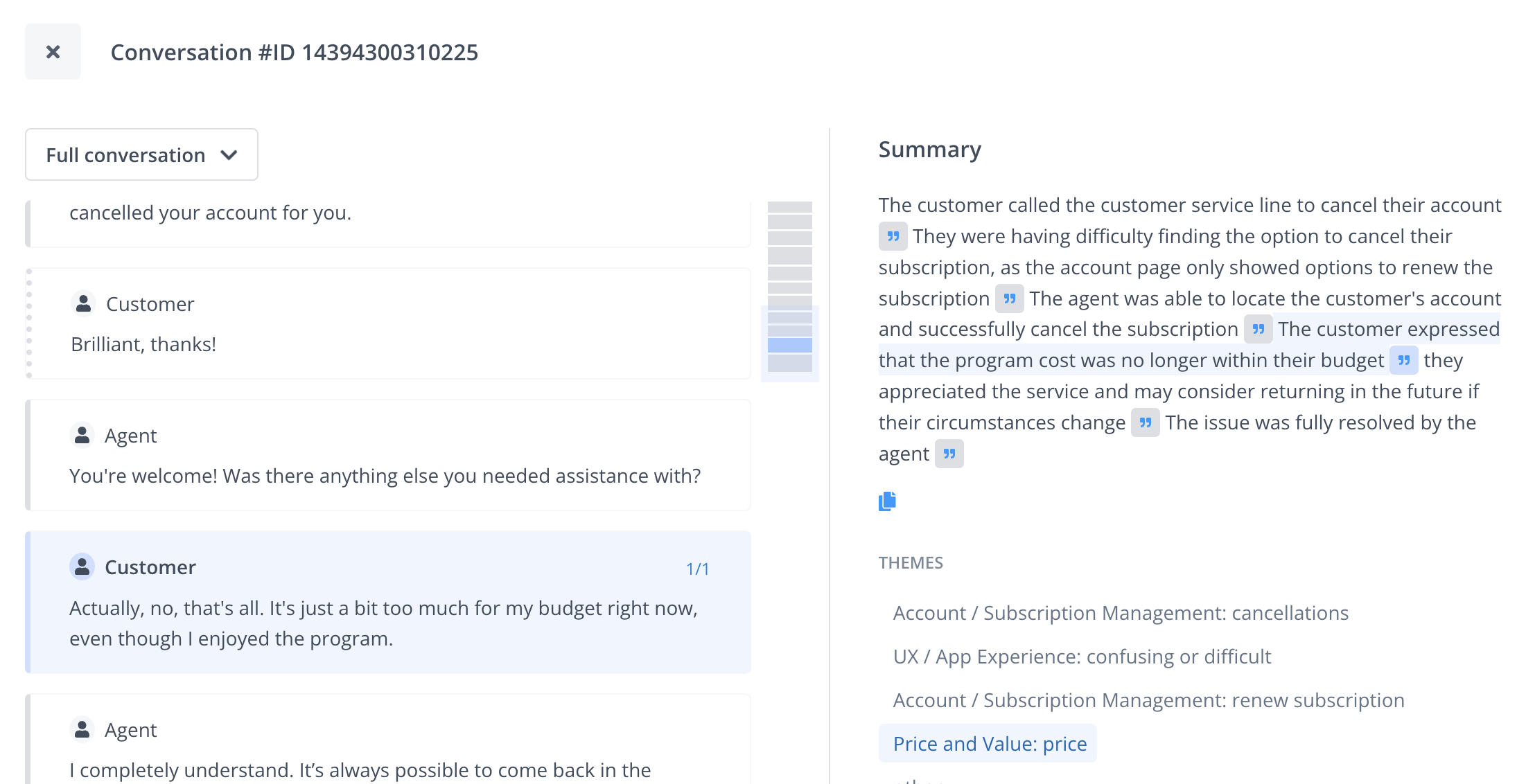
Similarly, an LLM can help you paraphrase a community forum post, a complaint or an email thread.
How to ensure accuracy and consistency
There are two areas of focus here: a) understanding user's accuracy needs, and b) ensuring you can deliver by choosing the right LLM and detailed prompt engineering.
Understanding user accuracy needs
What matters is not only how accurate themes are, but also how meaningful they are for your users. We talk about this in our quick guide on how to measure the accuracy of feedback analysis. You could get academic, and measure consistency of theming with a group of people.
If you use LLMs to find themes in your data, they'll be technically accurate but not always meaningful. Human feedback will be critical for this. We found this when analyzing a small feedback dataset using ChatGPT. There were several issues that are common to Generative AI, that you'll need to address:
- It latches onto a theme it “understands well” and ignores other themes.
- It is unable to combine themes because it lacks business knowledge.
- It is unable to combine themes because it lacks context
For example, in our test dataset, “Learner-led conferences” and “Parent-teacher interviews” were the same thing. In both cases, the child is updating the parent on their progress in front of a teacher. An LLM can't know such nuances. But, your users will need to teach it.

When you are building a feedback analysis solution in-house, you'll need to solve this. In Thematic, we designed a drag-and-drop UI to make it easy for our users to tell the AI how to analyze their feedback. We call it themes editing, and our guide on how to edit themes shows how to review themes to improve their accuracy.
You must also think about how to keep the analysis consistent over time. As new feedback comes in, how do you make sure it's analyzed in the same way as older feedback? If there are new themes, how can we add them in the right spot in your themes taxonomy?
Finding the most accurate LLM and prompt engineering
Selecting the right LLM is essential to deliver the accuracy and consistency of your feedback analysis platform. Not every LLM excels in every task; each model has unique strengths for specific analysis. The newest model on the market are not always the most effective for your specific needs. Switching to a new LLM can time-intensive, and constant updates may not yield substantial improvements.
Another vital steps in maximizing the accuracy of LLMs is crafting the right prompt. This is known as prompt engineering. You'll need to iterate and adjust the prompt for each task and type of data. This takes a lot of time and skills on how to evaluate the accuracy of each prompt.
At Thematic, we solve this by using a systematic pipeline that evaluates all available LLM models. We employ sophisticated algorithms to optimize our prompts based on evaluation benchmarks. This rigorous process ensures that we always deploy the most suitable model for each task. Our complete solution is a sequence of dozens of prompts that optimized for both accuracy, speed and costs. We also main a system that lets us easily upgrade our solution when a better model becomes available.
Data storage, ingestion, GDPR and compliance when building a feedback analytics solution
Before you start implementing the core analysis, it’s important to have the right data engineering and architecture.
Data storage
The data storage and architecture needs to support:
- easy ingestion of feedback
- adding rows with more feedback
- changes in format, e.g. new customer metadata or new date format.
If you only use one source of feedback, e.g. Qualtrics, it's less important. Your feedback platform itself can be used for storing and modifying feedback. But if you combine feedback from many sources, you'll need a high-performance data storage layer. The most common ones are Snowflake, Amazon Redshift, and Google BigQuery.
The models, prompts, supplementary data, and the code that applies them will also need to be stored somewhere.
Make sure your architecture supports querying the data in a fast way. This is essential for building repeatable and scalable feedback analysis solution.
Choosing the wrong data storage for feedback analysis can lead to many issues. Limitations in what queries you can run and slow response times can lead to poor user experience. As a result, your solution won't get used, which defeats the purpose of building one.
Ingesting data
You will need to create ways of getting data into your feedback analysis solution. They vary for each feedback channel, internal or external.
Your exact solution will depend on the number and the variety of feedback channels you'll need to support. Some might have an API, for others, you might need to build connectors. Tools like Zapier can simplify things. But still, this can be months of development work.
CSV exports can help you get started faster, but this approach is error prone in the long run.
In our experience, if data ingestion relies on manual processes, it likely won't be updated. It will go stale and make all the other work worthless.
So an API integration is much better in the long run. That said, some of the solutions/tools do not provide an API. We found that many feedback tools or public sites don't let you export your own feedback. Sometimes, you'll need to scrape the data.
Data gathering, cleaning and analysis
Make sure you have examples of typical datasets your users will need in their work. What metadata do they require? Make sure you store it in the right format.
Users will likely use this metadata as filters in their reporting. For example, they might want to run a report about feature requests by the highest paying customers from the last 6 months. Your data should support that.
If you end up working with CSVs, beware of formatting issues. The best format is UTF-8. Try not to open and save the file in Excel. Doing so may corrupt the data. For example, it can change date fields and identifiers into different formats that then won’t match the rest of the data.
Review the data manually to find any quirks of your datasets. Look for the type of feedback, the length of each piece, and any templated content like greetings with the live chat agent. Your solution will have to deal with these.
For example, if your dataset consists of complaints, there is no point focusing on sentiment analysis. Most of the things people will say will be negative.
After you have collected the data it is often necessary to clean it too. If the data was transcribed, you might have inaccuracies in agent/customer labels.
You might need to remove repeated headers, dividers, greetings, and such. Some language models can deal with these seamlessly, others can't.
Data Security
Using LLMs makes developing in-house possible, but it comes with some risks. Many companies now ban LLMs from third parties because it's not clear how they use the data. Sending data outside your network without security and compliance is risky. You can host open source LLMs like Llama or Mistral on your own infrastructure. But, this has its own cost and headaches.
Data Privacy (GDPR/CCPA)
Even if you keep the analysis in-house and don't use LLMs, it doesn’t mean you can ignore the relevant privacy laws.
Your company must be compliant with GDPR, CCPA or similar data laws. The necessary protocols must be maintained for subject data access requests etc.
There are a few things you could do to make this easier:
- Cleanse the data of all personally identifiable information (PII) (see how earlier in the article)
- Work with your security department to ensure compliance.
Further reading:
 Alyona Medelyan PhD
Alyona Medelyan PhD
How to build a visual front-end for reporting
At first glance, once you have structured the feedback, you should be able to visualize it. That's a fallacy. You'll deal with multi-variant data, which brings many challenges.
What does it mean, having multi-variant data? For each piece of feedback, you'll have multiple themes. Each theme might have sub-themes within it.
Will your users want a 3-level deep analysis? Can a theme be part of two categories? Will you need to visualize snippets of relevant source feedback, such as quotes? In a visualization, should theme frequencies add up to 100%?
There are many questions you'll need to think about and discuss with your users.
If you use Tableau, Looker or PowerBI for data visualization, you'll need to simplify. We've seen powerful PowerBI dashboards, so it's possible. But it takes time and they won't be pretty.
If you use custom visualization rendering, make sure they can process data fast. A beautiful but slow visualization isn't useful either.
Advantages and Disadvantages of Building Your Own Feedback Analysis Solution
Let's compare the Pros and Cons of building your own solution.
The Pros are easy:
- If you are only using self-hosted libraries, your data doesn't need to leave your company's private cloud environment. This of course doesn't include the most popular LLMs
- You can put huge volumes of feedback through it, especially with locally hosted language models.
- You can fully customize your solution for your company's use case.
- You can impress your boss with a cool demo!
The Cons are significant:
- It will take some months of research and development to build something that's truly useful.
- The highly skilled team working on creating an in-house feedback analytics solution will miss an opportunity to create something truly special for your customers that will set you apart from your competitors.
- Building your own feedback analysis solution demands significant investment in infrastructure. It'll need to support complex data handling and fluctuations in volume.
- You'll need a lot of documentation to make sure the solution can be maintained even after the skilled staff leave. With LLMs deprecating every 6 months, it's a non-stop endeavor.
- The costs can balloon but there will be a risk of low adoption.
Conclusions
We have brushed on many different aspects of designing a feedback analysis solution in house.
And yet, there's so much more that we haven't covered: scalability, a user friendly interface, best charts for visualizing feedback, a chat-like interface to interrogate the data.
LLMs make things seem easy. But, they are just one of the many parts of a usable solution for analyzing and sharing insights with your decision makers.
I often tell people that a CRM is a much easier solution to build, and yet, we buy them off the shelf for similar amount of money!
If you decide NOT to build your own solution, here's a great article on various thematic analysis software.
If you have further questions, I’d be happy to answer them.



